ML Fundamental Interview Review
Prepping for ML interviews - brushing up on fundamental stuff that may or may not come up in interviews.
CS 189 Notes
Link: Sahai Notes \(\DeclareMathOperator*{\argmin}{argmin} \DeclareMathOperator*{\argmax}{argmax}\)
Linear Regression
- We are trying to use a parametric model, where we have some \(w_d \in \mathbb{R}^d\) that controls the behavior of the function.
- We pick out some cost function that measures the quality of the hypothesis function’s predictions against the true output, and then solve by looking for \(w^* = \underset{w}{\argmax} L(w)\)
- The most basic way to solve is using OLS (Ordinary Least Squares), which assumes that our hypothesis function takes the form \(h_w(x) = x^Tw\), and we can solve by minimizing the mean squared error (\(L(w) = \sum\limits_{i=1}^n (x_i^Tw-y_i)^2 = \underset{w}{\min} \|Xw-y\|_2^2\)
- We can arrive at a closed form solution (one way is taking the gradient of the loss equal to 0 and solving for \(w^*\)) that tells us that \(w^*_{OLS} = (X^TX)^{-1}X^Ty\)
- The most basic way to solve is using OLS (Ordinary Least Squares), which assumes that our hypothesis function takes the form \(h_w(x) = x^Tw\), and we can solve by minimizing the mean squared error (\(L(w) = \sum\limits_{i=1}^n (x_i^Tw-y_i)^2 = \underset{w}{\min} \|Xw-y\|_2^2\)
Ridge Regression
- OLS has numerical instability and generalization issues
- Numerical instability can arise when the features are close to collinear, which causes the input matrix X to lose its rank, or have close to 0 singular values. This causes the \((X^TX)^{-1}\) term to have very large singular values, which can lead to very high values for \(w\), which can prevent generalization.
- The solution here is to penalize \(w\) from being too big, by adding a term to the loss to penalize the norm of \(w\). Thus the ridge regression loss is \(L(w) = \underset{w}{\min} \|Xw-y\|_2^2 + \lambda\|w\|_2^2\). The ridge regression solution (from taking the gradient of L to be 0), is then \(w^*_{RIDGE} = (X^TX + \lambda I)^{-1}X^Ty\).
- In addition, the hessian of the loss function is positive definite, so the loss function is strongly convex, and the ridge regression solution is unique
Feature Engineering
- If we want to model non linear functions, we can still use least squares - we just have to first construct a feature map that maps each raw data point \(x \in \mathbb{R}^l\) into a vector of features \(\phi(x)\). Note that \(\phi\) does not have to be a linear function. We can then solve for our hypothesis function \(h_w(x) = w^T\Phi(x)\), with least squares solution \(\underset{w}{\min}\|\Phi w - y\|_2^2\) (where \(\Phi\) is \(\phi\) applied to each data point in \(X\)).
- For example, if we want to solve for the equation of an ellipse, we can construct an equation of the form \(w_1 x_1^2 + w_2 x^2 + w_3 x_1 x_2 + w_4x_1 + w_5x_2 = 1\), and then formulate the problem with least squares, where the feature map is given by \(\phi(x) = (x_1^2, x_2^2, x_1x_2, x_1, x_2)\)
- In general, polynomials are universal approximators, but the problem with large polynomials is that the number of terms increases exponentially with the degree of the polynomial.
- The kernel trick can help get around this cost in certain cases
- In general hyperparameters can fall into two catagories - model hyperparameters that determine the structure of a model, and optimization hyperparameters that determine the optimization procedure
Previous Questions
- Given a machine with infinite GPU memory would we be able to train a deep learning model faster?
- Maybe not - if we want to do stochastic gradient descent, we need some fixed smaller batch size, and we can’t do it in parallel since we need to update the weights based on the gradients from each batch.
- What is the difference between LayerNorm and BatchNorm, why is normalization helpful, and when do we use one vs another and why?
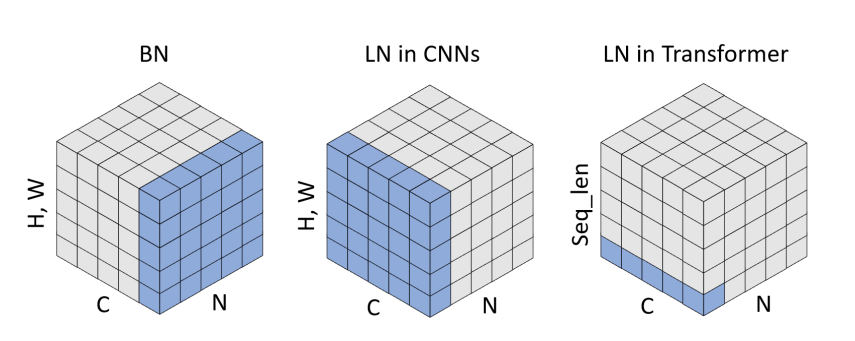
- The reason why normalization is useful in the middle of a deep learning model has a similar intuition to why it’s useful at all in the beginning - it keeps some numerical stability, and keeps the magnitude of the gradients similar throughout the model of the layers
- BatchNorm is generally used in CNNs and other image models. LayerNorm is more common in language and sequence modelling, since BatchNorm is tricky for RNNs, and doesn’t work well with small batch sizes. In LayerNorm for transformer models, an embedding is generated for each element in the sequence (regardless of whether or not its generated from an image patch or is a word embedding), and the LayerNorm operates over the embedding dimension, which means that there is no dependence on the sequence length dimension
- LayerNorm can also be applied the same way at training and test time, whereas for BatchNorm, you need to compute running mean and std averages for test time normalization, which may not work well across different sequence length inputs
- Explain Adam
- RMSProp + Momentum. RMSProp keeps a running average over the squared gradients, and normalizes the gradient with the square root of the running average. Momentum keeps a running average over the gradients, and uses it to inform the direction of the gradient.
- How to combat overfitting/What is regularization
- Reduce model size
- Regularization (L1, L2, Dropout, etc)
- Ensembling models
- Data Augmentation
- Explain the problem of vanishing and exploding gradients
- Gradients can either drastically increase or tend to zero as backprop happens - neither is desirable
- Vanishing gradients can be identified if the weights of early layers do not change very much relative to later layers
- Exploding gradients can be identified by NaN model weights or outputs due to overflow
- Solutions can include normalization (Batch/LayerNorm), reducing the number of layers, gradient clipping, and using better weight initialization
- ResNets also were motivated by solving this problem - the residual connections help gradient flow
- What’s the last paper/github repo that you pulled the code and ran?
- Explain how transformers work?
- In a sequence we can have repeat elements - how do we model these differently?
- Positional encoding - we use alternating sin/cosine functions to generate a vector with the same size as the embedding dimension, and add the two to create an embedding that includes the encoded relative position.
- Generally given a sequence of tokens, we want to model each token in the context of the rest of the tokens, so we can use the attention operation to generate a context embedding for each token. This is parallelizable, unlike LSTMs, so we can train these much faster.
- In a sequence we can have repeat elements - how do we model these differently?
- Give an example of a logistic regression model. Given inputs x (some d dimensional vector) and y (some class label), how do we train a model to predict labels given inputs. Define a loss and calculate and expression for backpropping this loss to update weights.
- Logistic regression is a 1 layer neural network, where we apply a linear projection, then a softmax (multi-class) or sigmoid (binary classification) in order to get a probability distribution per class. We can then use a negative log likelihood loss
- What is Maximum Likelihood Estimation?
- What are ensemble models and when are they useful?
- What is self attention, and where is the weighted sum computed in the self attention operation?
- What is the difference between CNNs and ViTs?
- What is a Hessian and where is it used in ML?
- What is a Positive Definite Matrix
- What is necessary for a square matrix to be invertible?
- What does it mean for the covariance matrix of a multivariate gaussian to be diagonal?
- When would you use threads vs processes?
- How would you pass data at the OS process level between one dataloading process and a data processing process
- Difference in weights between L1 and L2 regularization?
- What is the entropy of a biased coin?
- Explain Binary Cross Entropy
Generic ML Questions
- Explain the Bias Variance Tradeoff
- Bias quantifies how close our model fits to the given training set. Low bias indicates that our model fits well to the given training set, while high bias indicates that we haven’t fit well to the training set.
- Variance quantifies how well our model generalizes to an unseen test set. Low variance indicates that our model performs similarly on other datasets as it does on the training set. High variance indicates that the model performs worse on unseen data compared to its performance on the training set.
- In general, using regularization helps decrease variance while increasing bias. Increasing model complexity usually reduces bias while increasing variance.
- The bias variance tradeoff in classical ML setting suggests that lower bias will lead to higher variance, and vice versa. The double descent phenomenon in deep learning shows that the bias variance tradeoff may not be as applicable for non-classical ML settings (i.e. making models bigger and bigger can be good)
- Explain the difference between precision and recall
- Given a binary classifier:
- Precision is defined as the number of correct positive predictions divided by the number of positive predictions
- Recall is the number of correct positive predictions divided by the number of actual positives
- Given a binary classifier:
Computer Vision Questions
- What operations exactly happen during a convolution?
- Element wise multiplication and addition
- Explain the concept of a receptive field
- More specifically, if you have two 3x3 convolutional filters, with a stride of 1, and you pass them over the image successively, what is the receptive field of an element of the output
- Each element in the final activation will have a receptive field of 5x5
- More specifically, if you have two 3x3 convolutional filters, with a stride of 1, and you pass them over the image successively, what is the receptive field of an element of the output
Coding Questions
- Given codebase that does some segmentation task - fill in the data loading step (i.e. we have a folder containing the data, and if we want to get_item some image in that folder what do we do), then fill out a basic forward class given some building blocks (i.e. Given Conv2D, Upsample, ReLU, BatchNorm, MaxPool2D, put together a forward function that does the segmentation task)
ML Design Questions
- How can we train a model given image data, LIDAR data, and text data to do open vocabulary object detection?
- How could we blur faces from a dataset of images from self driving cars?
- Assuming that we have access to more data than we can reasonably label, how could we train a model to label most of the data for us?
- How do we frame the task?
- We could do segmentation or bounding boxes - segmentation is meaningfully more complicated in terms of obtaining training data (and maybe in terms of implementation and model complexity)
- This is actually just object instance segmentation - we could use something like a Mask R-CNN model to solve this
- What are the evaluation metrics we could use?
- IoU metric for how well a prediction overlaps with the labeled face (we could also have considered MSE for the case of segmentation)
- What would the labelling task look like, and roughly how big would the labeled dataset be?
- What model and what loss function?
- Mask R-CNN - the loss function in the Mask R-CNN is a combination of the negative logprob for the true class, a bounding box loss (smooth l1 on the 4 bounding box predictions), and a mask loss, which uses a per pixel sigmoid, and then takes an average of the binary cross entropy loss across the mask pixels.
- How could we deal with different data sources - i.e. we have data from a fish eye and a traditional camera
- We could either consider transforming the images from one to another using some CV library, or training separate models for the different data types, since it might be difficult for a model to simultaneously learn features from both camera types. If we were to keep one model, we would want to balance out the distribution of images across the datatypes in order to make sure performance is good on both.
- How do we frame the task?
- Assuming that we have access to more data than we can reasonably label, how could we train a model to label most of the data for us?
- You’ve been given an archive of satellite photos of Cambodia, each taken a few years apart, and you want to count the number of homes in the region at each time period. You can get labels for a set of areas containing at least 10,000 homes via crowdsourcing, but there are too many photos to do a full manual count. What sort of ML pipeline would you use to automate this task.
- Followup: How would you store the dataset to optimize for the dataloader
- Followup: If while training this model, you see that the GPU utilization is at 30%, what would you do to fix it?