Surgical Fine Tuning Improves Adaptation to Distribution Shifts
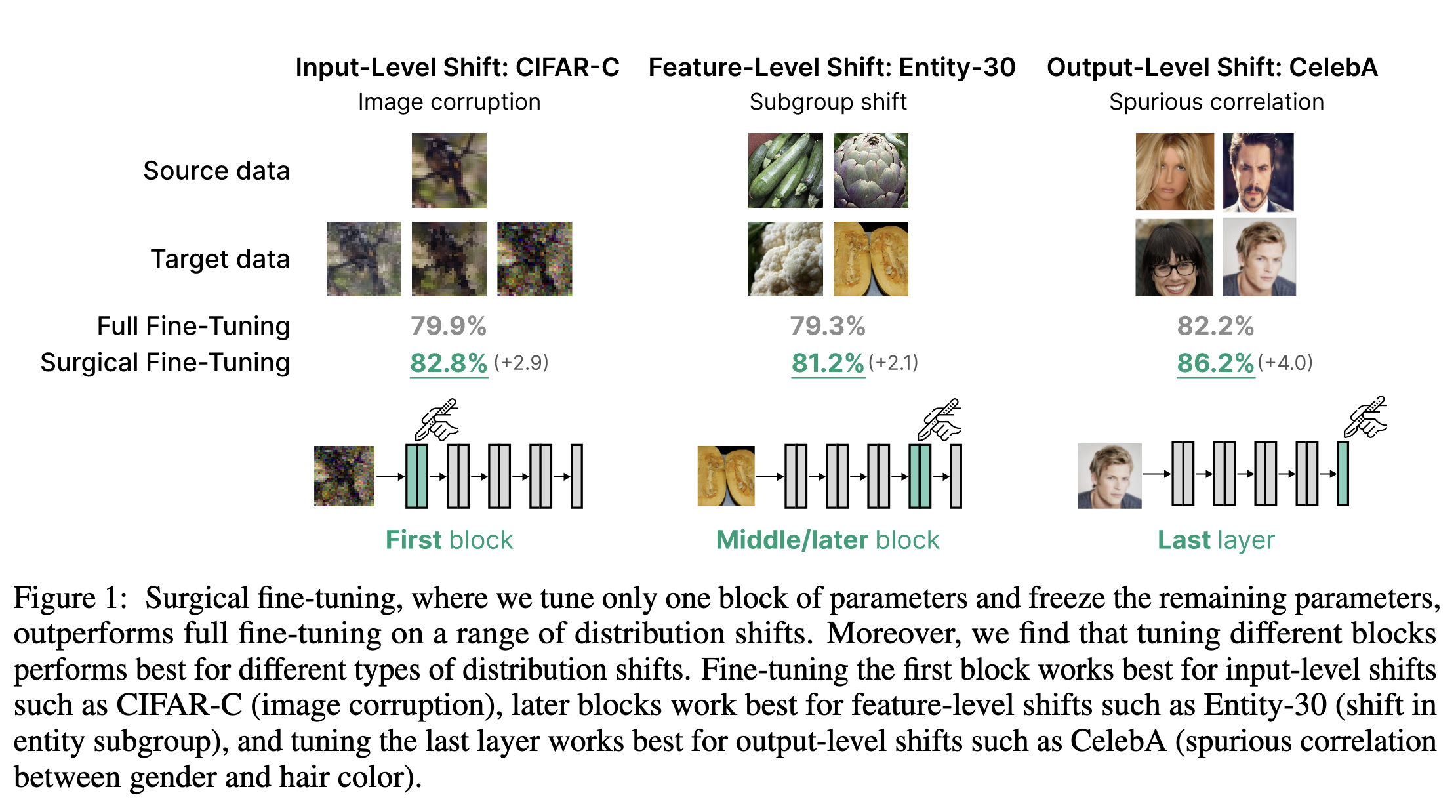
This paper presents “surgical fine tuning”, which involves selectively fine tuning certain blocks of pretrained models, as a method for improving adapation to distribution shifts given small amounts of labeled in-domain data. The authors find that for input level shift, tuning only the early layers performs the best, for feature level shift (i.e different subgroups from the same class existing in the source/target domains), tuning intermediate layers works better, and for label shift (i.e. spurious correlations), tuning the last layer works the best. The authors validate this across 7 datasets (CIFAR-C, ImageNet-C, Living-17, Entity-30, Waterbirds, CIFAR-Flip, and CelebA) using mostly imagenet pretrained ResNets. The authors then provide a theoretical analysis and framework by examining a 2 layer neural network, and determining why tuning the first layer works better for input shift, and the last layer works better for label shifts. Finally, the authors propose auto-RGN (Relative Gradient Norm) and auto-SNR (Signal to Noise Ratio) as methods for freezing or downweighting certain layers while fine tuning. Auto-RGN is used to obtain a per tensor learning rate based on the ratio of gradient norm to parameter norm. Auto-SNR is used to choose which layers to freeze by setting a threshold of SNR after values are normalized to be from 0-1. Auto-RGN is found to work better, and the authors further investigate which layers are found by Auto-RGN to be more important to certain distribution shift. Future work that is suggested includes closing the gap between their proposed Auto-RGN method, and the best surgical fine tuning result by understanding which layers have stronger relationships to certain distribution shifts.
Notes and Questions:
- This paper is a domain adaptation paper, and it assumes access to a small amount labeled target domain data for improving distribution shift
- What if we didn’t have labeled target domain data? Does the intuition of surgical fine tuning hold for unsupervised domain adaptation methods?
- The papers that they cite (ERM May Already Learn Features Sufficient for Out-of-Distribution Generalization, Last Layer Retraining is Sufficient for Robustness to Spurious Correlations) both suggest that in reality, backbones of models trained with ERM actually learn pretty good features, even in the presence of distribution shift or spurious correlations, and we can get pretty good performance from just tuning the linear classifier layer
- Seems like this paper supports the claim of Last Layer Re-training in that they find that tuning the last layer of a model is the best for mitigating spurious correlation
- I’m dumb and didn’t finish reading the paper before writing this note: it’s addressed in section 2.2 - the authors find that the intuition holds for unsupervised settings (they only test on CIFAR-C and Imagenet-C, and find that tuning earlier layers improves over full fine-tuning in the “online” setting)
- The papers that they cite (ERM May Already Learn Features Sufficient for Out-of-Distribution Generalization, Last Layer Retraining is Sufficient for Robustness to Spurious Correlations) both suggest that in reality, backbones of models trained with ERM actually learn pretty good features, even in the presence of distribution shift or spurious correlations, and we can get pretty good performance from just tuning the linear classifier layer
- What if we didn’t have labeled target domain data? Does the intuition of surgical fine tuning hold for unsupervised domain adaptation methods?
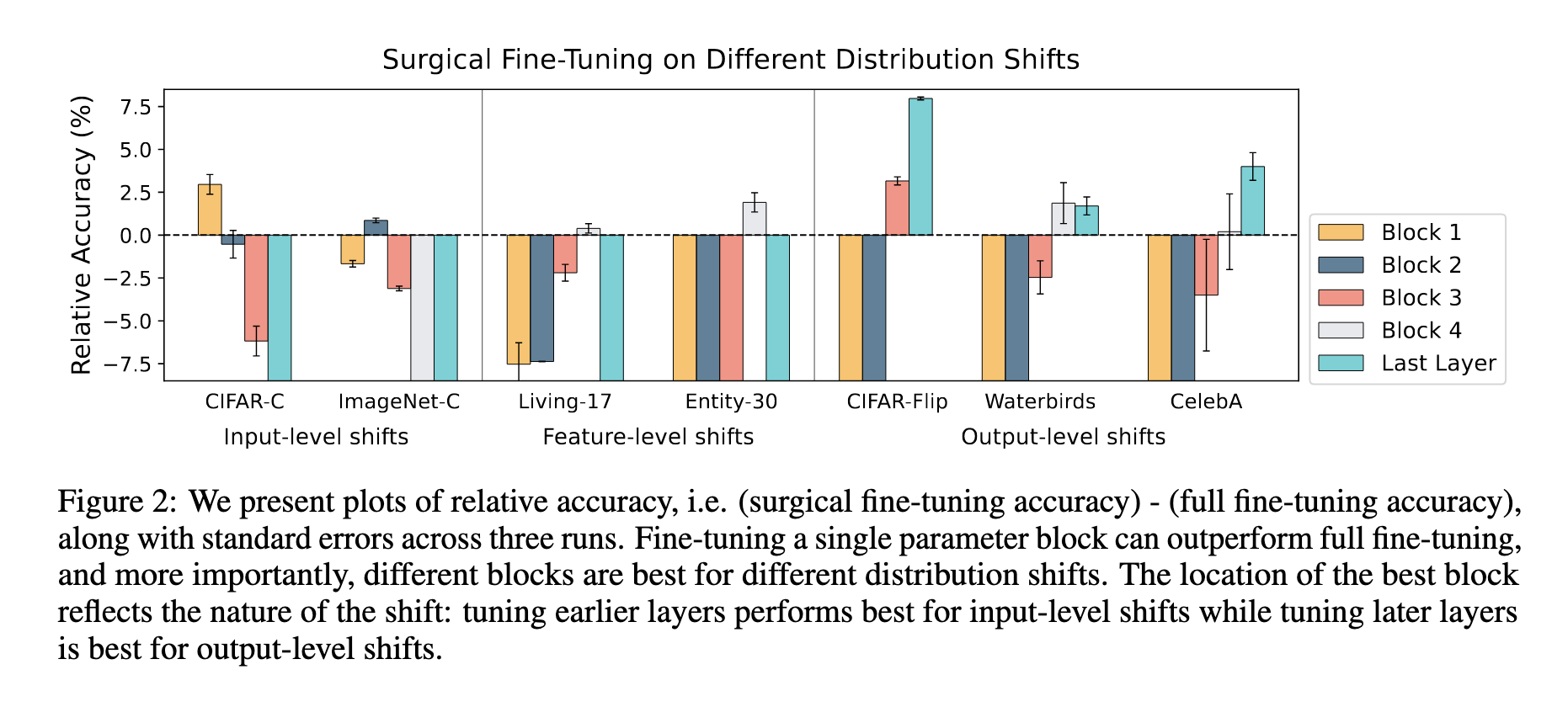
- These experiments are pretty surprising to me - how dramatic the differences are seems strange
- Specifically on Entity-30, the one positive result being tuning block 4, but block 3 being equally bad as blocks 1 and 2 is surprising - why is that the case fo the Entity-30 but not Living-17?
- I wonder what this would look like if you did this on ViTs for all of the datasets instead of just Camelyon and FMoW? What about the effect of pretraining objectives - they seem to be assuming supervised ImageNet pretraining, but in the era of ViT models, you have pretty dramatically different representations from MIM and CL models, and so this overall intuition of training early layers for input shift, and training the last layer for spurious correlation might not hold. The method for automatically selecting layers to train is still interesting in that case though, and even the insight that there is a right layer or subset of layers to tune is pretty interesting and worth investigating