TinyImageNet Challenge
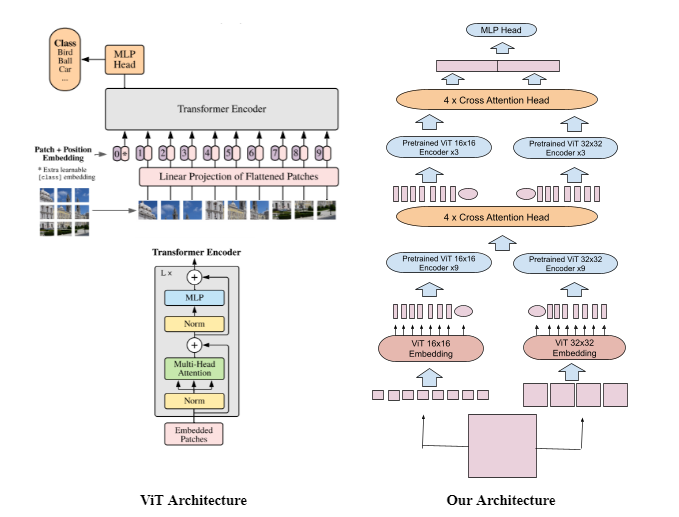
The emergence of Vision Transformers in late 2020 brought on a variety of new architectures into the space of image classification - however, work on robustness of ViT based models (e.g. Swin Transformer, CaiT, DeiT, PiT) as compared to more traditional convolution based approaches is still emerging.
Motivated by trying to gain understanding of the robustness of ViT based models, in this project, we attempted a number of different techniques for building a robust classifier for the Tiny ImageNet challenge. Vision Transformers have tentatively been shown to potentially help improve robustness against out of distribution examples from both white box and black box attackers as compared to Convolutional Networks.
We report a top 1 validation accuracy of 81% on our architecture from fine tuning on Tiny ImageNet, using vision transformer blocks that were pretrained with ImageNet 1k, and using standard data augmentations along with AugMix. Our architecture, loosely based off of CrossViT from Chen et al., shows performance improvements over a standard ViT model via parallel vision transformers attending to different image patch sizes combined with cross attention and an MLP head. We also observe faster training and higher clean accuracy compared with deeper stacked ViT architectures with similar numbers of parameters. We benchmark robustness and accuracy of our model against a variety of ViT and ResNet based models on Tiny Imagenet-C and with adversarial attacks from Foolbox, and evaluate the addition of cross attention and varying patch sizes, as well as the use of sparse attention, to classifying out of distribution images.